UglyCasanova wrote:A compression artifact is a noticeable distortion of media (including images, audio, and video) caused by the application of lossy data compression.
Lossy data compression involves discarding some of the media's data so that it becomes simplified enough to be stored within the desired disk space or be transmitted (or streamed) within the bandwidth limitations (known as a data rate or bit rate for media that is streamed). If the compressor could not reproduce enough data in the compressed version to reproduce the original, the result is a diminishing of quality, or introduction of artifacts. Alternatively, the compression algorithm may not be intelligent enough to discriminate between distortions of little subjective importance and those objectionable to the viewer (Read: Youtube's codec. This will be made evident later).
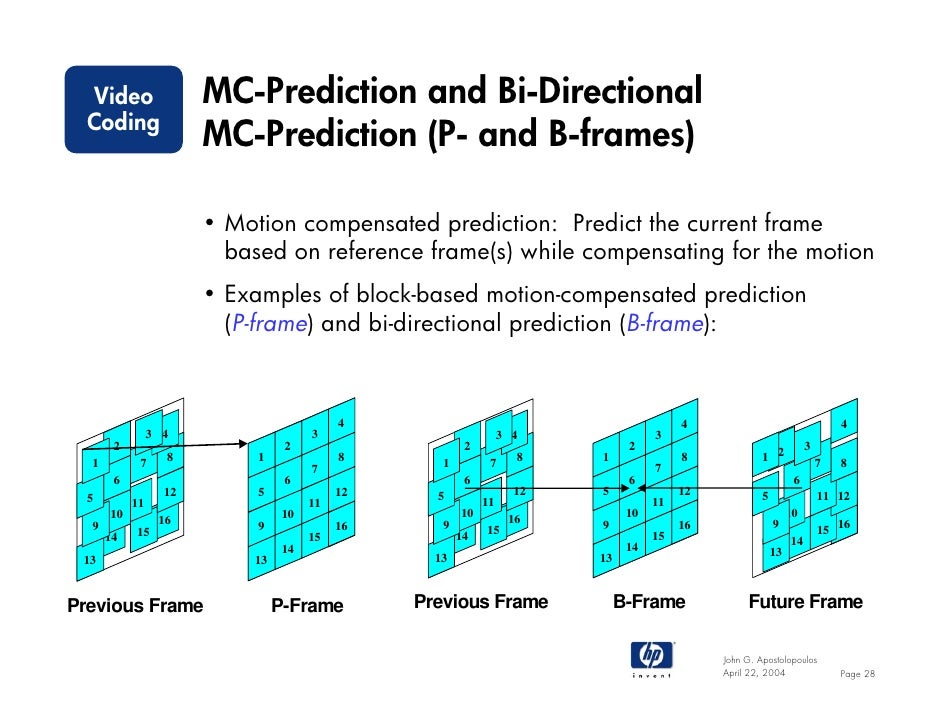
In the field of video compression a video frame is compressed using different algorithms with different advantages and disadvantages, centered mainly around amount of data compression. These different algorithms for video frames are called picture types or frame types. The three major picture types used in the different video algorithms are I, P and B. They are different in the following characteristics:
I‑frames are the least compressible but don't require other video frames to decode.
P‑frames can use data from previous frames to decompress and are more compressible than I‑frames.
B‑frames can use both previous and forward frames for data reference to get the highest amount of data compression.

A frame is a complete image captured during a known time interval, and a field is the set of odd-numbered or even-numbered scanning lines composing a partial image. When video is sent in interlaced-scan format, each frame is sent as the field of odd-numbered lines followed by the field of even-numbered lines.
Frames that are used as a reference for predicting other frames are referred to as reference frames. In such designs, the frames that are coded without prediction from other frames are called the I-frames, frames that use prediction from a single reference frame (or a single frame for prediction of each region) are called P-frames, and frames that use a prediction signal that is formed as a (possibly weighted) average of two reference frames are called B-frames.
In the latest international standard, known as H.264/MPEG-4 AVC, the granularity of the establishment of prediction types is brought down to a lower level called the slice level of the representation. A slice is a spatially distinct region of a frame that is encoded separately from any other region in the same frame. In that standard, instead of I-frames, P-frames, and B-frames, there are I-slices, P-slices, and B-slices.
Typically, pictures (frames) are segmented into macroblocks, and individual prediction types can be selected on a macroblock basis rather than being the same for the entire picture, as follows:
I-frames can contain only intra macroblocks
P-frames can contain either intra macroblocks or predicted macroblocks
B-frames can contain intra, predicted, or bi-predicted macroblocks
Intra coded frames/slices (I‑frames/slices or Key frames)
I-frames are coded without reference to any frame except themselves.
Typically require more bits to encode than other frame types. Very high quality. Used on DVDs and streamed television broadcasting. Although high quality, it is not without its flaws. Drop in stream speed and/or hardware errors can occur and cause the same sort of glitches as those found in highly compressed video files.
Predicted frames/slices (P-frames/slices)
Older standard designs (such as MPEG-2) use only one previously decoded picture as a reference during decoding, and require that picture to also precede the P picture in display order.
Bi-directional predicted frames/slices (B-frames/slices)
Require the prior decoding of other frame(s) in order to be decoded.
May contain image data and motion vector displacements or both.
H.264 can use one, two, or more than two previously decoded pictures as references during decoding, and can have any arbitrary display-order relationship relative to the picture(s) used for its prediction.
(Spoiler alert: YouTube uses H.264 as their video codec, which is compressing an already compressed file)
 Motion compensation block boundary artifacts (AKA what you are seeing)
Motion compensation block boundary artifacts (AKA what you are seeing)
Block boundary discontinuities can occur at edges of motion compensation prediction blocks. In motion compensated video compression, the current picture is predicted by shifting blocks (macroblocks, partitions, or prediction units) of pixels from previously decoded frames. If two neighboring blocks use different motion vectors, there will be a discontinuity at the edge between the blocks.

